 Here we have another New Guild Shape guitar from the late 1970s called an S-60. I had wanted a Guild S-60 for some time and the only one I’d found was listed at $1200 which is hundreds more than I paid for my S300. This one popped up on eBay with some not-so-great pictures and a less-than-stellar description with an nice opening bid. Since I was the only one who bid I got it for a great price!
Here we have another New Guild Shape guitar from the late 1970s called an S-60. I had wanted a Guild S-60 for some time and the only one I’d found was listed at $1200 which is hundreds more than I paid for my S300. This one popped up on eBay with some not-so-great pictures and a less-than-stellar description with an nice opening bid. Since I was the only one who bid I got it for a great price!
The S-60 is the entry-level into the Guild electric guitars of the era and if you’ve read my other reviews you’ll know that I have a thing for high-end Guilds, but as you’ll read I have a soft spot for these guitars as well. Let’s take a look and see if this 1977 Guild S-60 holds up to my fond memories.
Introduction
 In or around 1977 Guild introduced the new Guild guitar shape which was used on the S-60, S-65, S-70, S-300 and others I’ve probably missed. You may have noticed the same shape on the S-300 I raved about here. If you’ve been drinking don’t worry; this pic is the S-300. It’s red, so it confused me, too, though I won’t admit to drinking anything but Coke.
In or around 1977 Guild introduced the new Guild guitar shape which was used on the S-60, S-65, S-70, S-300 and others I’ve probably missed. You may have noticed the same shape on the S-300 I raved about here. If you’ve been drinking don’t worry; this pic is the S-300. It’s red, so it confused me, too, though I won’t admit to drinking anything but Coke.
The S-60 was the entry level model of these guitars and if you look at the one in this review you’ll see that it has a number of differences from the S-300 including the most obvious fact that the S-60 has only one pickup.
One-pickup guitars are sort of an anomaly in the world of rock music because most of them were designed to be entry-level or beginner guitars, much like the S-60 itself. Consider the Gibson Les Paul Junior. With its non-bound fretboard, single P90 pickup and utterly simple operation, it was basically a Les Paul stripped down to its bare necessities. The reason I call them anomolies is because the low-cost beginner level guitars make some of the most iconic hard-rock sounds in the history of the genre. They are absolute tone monsters in a simple inexpensive package and have been favored by some of the most popular rock bands in history. So it is with the S-60, you know, except for the part about being favored by famous people.
 The Guild S-60 is similar to the other S-series Guilds of the time but without any of the finer details evident on the upper-scale models like the S-300. Where the S-300 has an ebony fretboard, the S-60’s is rosewood. While the S-300 has excellent Gotoh tuners, the S-60 is much cheaper inline tuners that don’t come close to the quality of the high-end stuff.
The Guild S-60 is similar to the other S-series Guilds of the time but without any of the finer details evident on the upper-scale models like the S-300. Where the S-300 has an ebony fretboard, the S-60’s is rosewood. While the S-300 has excellent Gotoh tuners, the S-60 is much cheaper inline tuners that don’t come close to the quality of the high-end stuff.
Some of the parts are the same, though. The Guild HB-1 pickup is the same model used in the S-300, as is the bridge and tailpiece. The build quality of the guitar (covered later) is also at the same level as the pricier S-300. It plays damn-near as well, too! It doesn’t have things like fancy phase switches or high-end headstock laminates, but you know what? Headstock laminates don’t make guitars sound better.
Just as I have a soft spot for Guild S-300s, I have thing for these lower-prices S-60s, too, because my first nice guitar was a sunburst S-60 that I bought from a friend back around 1979. That guitar is the reason I love Guilds. It is also the reason that I lusted for years after the beautiful Guild S300A-D hanging in Mikes’ Music that I finally bought and kept as my only instrument for over 20 years. The Guild S-60, though, was my first.

That first S-60 came in a terrible chipboard case that more or less protected the guitar from something, I guess. Man, how I hated that case, but it did the job for years until I gave the guitar to my cousin. The chipboard case was another means of keeping the price of the guitar down, and it worked because it was probably worth about twelve dollars, though to be fair, those were twelve 1977 dollars and not the recession-riddled psuedobucks of today.
That original Guild S-60 served me well, and it was my main guitar through much of high school and was the guitar on which I learned the seminal rock song of the time: Locomotive Breath by Jethro Tull. One of my favorite memories (aside from the great overdriven tape deck distortion via coily cord one illustrated here) comes from my days in the high school stage band. Allow me to digress.
There were two jazz bands in high school. The first, called the Jazz Band, was for the kids who could do things like read music. The kids who couldn’t make the Jazz Band but who sill wanted to play ended up in the Stage Band, and of course that’s where I ended up. It was the Jazz Band for losers, and I was their lead guitar king.
 One fine Sunday in New Jersey, while attending the Chester Flea Market in the very early ’80s, I stumbled across a band that was selling all its stuff including these two Traynor PA columns and a Peavey head, the entire set of which I bought for $100. That was my guitar amp for a time (it’s amazing what you can do with a Big Muff Pi and volume) and what you see in the pic is what it looked like in my teenager’s bedroom from about 1980, blue shag rug and all.
One fine Sunday in New Jersey, while attending the Chester Flea Market in the very early ’80s, I stumbled across a band that was selling all its stuff including these two Traynor PA columns and a Peavey head, the entire set of which I bought for $100. That was my guitar amp for a time (it’s amazing what you can do with a Big Muff Pi and volume) and what you see in the pic is what it looked like in my teenager’s bedroom from about 1980, blue shag rug and all.
Yes, my mother was a saint.
At any rate, one day for Stage Band practice I pulled one of those columns out of the back seat of my 1969 Ford Torino and proceeded to haul it into the band room, hook it up to the head, and plug in the Big Muff Pi. I then sat down, and when the conductor gave the queue I blew away not only the solo to Caroline And Her Magic Cello Enter The World Of Jazz Rock, but also all of the sheet music from all of the music stands in the room. Hey, it’s not like any of us could read those charts, anyway. I’m sure I’m a legend to this day, though I still doubt the veracity of the comment given me by a Jazz Band judge some time later that year who told me that, “You have a good feel for the Rock idiom.”, which I always assumed meant, “please stop playing jazz.”
What can I say? This is simply not a jazz guitar. That’s why I was stuck in the stage band; I blamed the guitar instead of practicing more. Hey, why practice when you can just buy more speakers? Did I mention how loud it was?
Finish
 This guitar is finished in cherry red and is coated in lacquer. I know all S-60s and their ilk are lacquer-coated because I’ve seen scores of them over the years, most of which have very nice examples of lacquer checking in the finish. This one does not, though it does have a bit of wear on the top edge right where the big ol’ bell-bottom starts.
This guitar is finished in cherry red and is coated in lacquer. I know all S-60s and their ilk are lacquer-coated because I’ve seen scores of them over the years, most of which have very nice examples of lacquer checking in the finish. This one does not, though it does have a bit of wear on the top edge right where the big ol’ bell-bottom starts.
I found this guitar on eBay with some less than stellar pictures and a description that included the following: “The color is a stained red, wood grain can be seen through the stain.” Um… what? Did someone strip this guitar and then stain it red? I’ve seen some wacky things in my day, but this guitar looked like it might be original, and since the S-60 originally came in cherry, black, walnut, natural, or white, I took a chance that this was the original cherry finish. Score! The guitar was much better than expected. Let that be a lesson to all you eBayers out there: Take good pictures and describe the guitar well! This guitar would have likely sold for hundreds more with better pics and an accurate description.
This guitar does have a bit of what looks like finish cracks at the nut which runs for a fret or two and follows the fretboard. I didn’t even notice this while playing it, and they only became obvious after very close examination. Examination with a UV light shows no signs of repair, though it does show a bit of wear that’s not obvious in regular light. This is a forty year old entry-level guitar after all, so it can be forgiven the odd wrinkle.
Fretboard and Neck
 This guitar has an unbound rosewood fretboard with what are likely pearloid dot inlays. The fretboard is a little blotchy in spots since this was a low-end model, but it still looks better than some of the rosewood I see on guitars these days. The frets measure about .02″ high by .10″ wide which are the same “wide” frets found on all my Guild electrics from this era.
This guitar has an unbound rosewood fretboard with what are likely pearloid dot inlays. The fretboard is a little blotchy in spots since this was a low-end model, but it still looks better than some of the rosewood I see on guitars these days. The frets measure about .02″ high by .10″ wide which are the same “wide” frets found on all my Guild electrics from this era.
The neck’s width at the nut is 1 21/32 which is halfway between 1 5/8″ and 1 11/16″. The neck is actually *just* a bit wider on this guitar that it is on my S300 but it’s not something anyone would notice unless they’re as nutty about neck widths as me. The neck is one-piece maple 24 3/4″ scale and came to me as straight as could be. It is also a 24-fret neck just like all the S-series from this era, so there are lots of notes to be had way up high if you dare.
 The fretboard radius was a bit of a challenge for me to measure. At first I got 9.5″ which is where my S300 measured, but then I was convinced that maybe it was 7.25″. I measured again and in a fit of frustration just put down the tools and started playing. This is not a guitar for measuring; it’s a guitar for playing Locomotive Breath until your fingers bleed!
The fretboard radius was a bit of a challenge for me to measure. At first I got 9.5″ which is where my S300 measured, but then I was convinced that maybe it was 7.25″. I measured again and in a fit of frustration just put down the tools and started playing. This is not a guitar for measuring; it’s a guitar for playing Locomotive Breath until your fingers bleed!
After my fingers hurt I turned up the light again and measured once more with my magnifier and I have to say that this guitar has a 7.25″ fretboard. This is the first Guild electric I’ve measured with such a curved board, and since the prevailing Internet wisdom is that a rounder board will fret out when bending strings, I had a hard time believing it. That’s when I remembered that a well set-up guitar will not fret out, and this guitar is set up remarkably well.
Build Quality
 Like every Guild electric I’ve played, the build quality is fabulous on this guitar. It’s not without its minor issues which I’ll cover throughout this article, but most of them can be forgiven because this was designed to be an entry level guitar from 40 years ago. I can tell you that it feels just like my much more pricey and richly appointed S300, and that’s a big deal to me, though to be fair I do notice a feeling of refinement on the S300 that I chalk up mostly to the ebony fretboard.
Like every Guild electric I’ve played, the build quality is fabulous on this guitar. It’s not without its minor issues which I’ll cover throughout this article, but most of them can be forgiven because this was designed to be an entry level guitar from 40 years ago. I can tell you that it feels just like my much more pricey and richly appointed S300, and that’s a big deal to me, though to be fair I do notice a feeling of refinement on the S300 that I chalk up mostly to the ebony fretboard.
The guitar is amazingly resonant, the neck joint is beautiful (just like my S300), and the fretwork is very nice with no rough spots or snags anywhere to be found.
 This S-60 is mahogany just like my S300 but this guitar weighs in at 6 lbs 11 oz which is amazingly light. I noticed this right away when I picked it up since the S300 I have in my possession right now weighs a full pound more and the S300A-D I used to own weighed even more than that because it was ash. Certainly the S300 has twice as many pots, an additional pickup, and much beefier tuners, but I would argue that the S300 has more wood routed out of it so I’m chalking the light weight up to this just being an excellent piece of wood. The body does measure 1/64″ thinner than my S300, but I find it hard to believe that that adds up to a pound of wood.
This S-60 is mahogany just like my S300 but this guitar weighs in at 6 lbs 11 oz which is amazingly light. I noticed this right away when I picked it up since the S300 I have in my possession right now weighs a full pound more and the S300A-D I used to own weighed even more than that because it was ash. Certainly the S300 has twice as many pots, an additional pickup, and much beefier tuners, but I would argue that the S300 has more wood routed out of it so I’m chalking the light weight up to this just being an excellent piece of wood. The body does measure 1/64″ thinner than my S300, but I find it hard to believe that that adds up to a pound of wood.
 One of the ways you notice right away that this is a lower-priced guitar is the lack of the iconic Guild chesterfield logo on the headstock. In fact, there is no veneer at all and the mahogany wood shines through the beautiful cherry finish. The tuners are also an obvious downgrade from the nicer S300, but we’ll talk about those a bit later. The Guild logo on the headstock has faded a bit over time and it’s likely just a transfer decal as opposed to the wonderful inlays found on the S300s.
One of the ways you notice right away that this is a lower-priced guitar is the lack of the iconic Guild chesterfield logo on the headstock. In fact, there is no veneer at all and the mahogany wood shines through the beautiful cherry finish. The tuners are also an obvious downgrade from the nicer S300, but we’ll talk about those a bit later. The Guild logo on the headstock has faded a bit over time and it’s likely just a transfer decal as opposed to the wonderful inlays found on the S300s.
 This is really a very nice guitar that is striking in its red finish with the contrasting black pick guard.
This is really a very nice guitar that is striking in its red finish with the contrasting black pick guard.
One of the things I dislike about the Strats I’ve played is that the pickguard feels hollow to me and that makes the guitar feel cheep. I have an American Deluxe Strat from 2008 that feels like this and for the $1200 I paid for it back then, it’s really a very disappointing experience every time I play it. With the large pickguard on the Guild S-60, I was a bit worried that I would have the same experience, but there is nothing like that going on with this guitar. That could be due to the roughly 384 (16) screws holding that pickguard onto the guitar or it could be the fact that there is no additional routes under the guard. Either way, I love the way it feels.
Pickup
 This guitar came to me with the original HB1 in the case because someone had replaced it with a Gibson Classic ’57. When I got the guitar I plugged it into make sure everything worked, played it a bit, then tore it apart in order to restore the guitar to its former glory.
This guitar came to me with the original HB1 in the case because someone had replaced it with a Gibson Classic ’57. When I got the guitar I plugged it into make sure everything worked, played it a bit, then tore it apart in order to restore the guitar to its former glory.
Why anyone would replace the chimey articulate Guild HB-1 with the most generic of “I wish I was a real PAF” Gibson wannabe pickups is beyond me, but the original pickups is back where it belongs. Thank you to whoever decided to keep the original in the case. People like me really appreciate stuff like that.
 Sadly, the person who felt that the guitar had too much character and needed it to sound more generic also decided to drill a new hole into the impossible to replace original Guild S-60 pickguard. Luckily no structural harm was done but there’s now an additional hole along with an ugly chip in the guard. The good news is that the HB-1 sounds so damn good that I instantly forget about the hole after the first strum.
Sadly, the person who felt that the guitar had too much character and needed it to sound more generic also decided to drill a new hole into the impossible to replace original Guild S-60 pickguard. Luckily no structural harm was done but there’s now an additional hole along with an ugly chip in the guard. The good news is that the HB-1 sounds so damn good that I instantly forget about the hole after the first strum.
The HB-1 in this guitar measures 6.76k Ω which is nicely in the low-wind range but a bit lower than I’m used to seeing in a bridge HB-1. Since there is only one pickup, the guitar nerd part of my brain is doing all sorts of machinations insisting that the guitar should sound better because there’s no neck pickup pulling on the strings. Is it true? I don’t know, and I don’t care. All I know is that this guitar rocks. Notice how I didn’t say that this guitar jazzes? That’s the lack of practice talking. Hang on while I make it louder…
Electronics
 This guitar has one pickup, one volume knob, and one tone knob. The only way it could be simpler is if it had no tone knob or even no knobs at all.
This guitar has one pickup, one volume knob, and one tone knob. The only way it could be simpler is if it had no tone knob or even no knobs at all.
Since everything is mounted to the pick guard it’s very easy to examine the components, which of course I did with gusto. The tone pot is marked 004029 3047441 and measures 179k Ω making it a 200k Ω pot (pots are generally sourced with +/- 20% accuracy.
The volume pot is marked 004020 3047149 and measures 458k Ω making it a 500k Ω pot. The capacitor is a green polyester film cap marked as 100v and .047pF. Again, note the conspicuous lack of giant snake oil super-caps in Guild electric guitars.
 The pot codes indicate that these are Stackpole Electronics pots manufactured in the 41st and 49th weeks of 1974. This set of three Stackpole Pots from 1961/2 sold for $590 which is more than I paid for the entire guitar! That, of course, means nothing but it was one of the first pages I found when searching for “stackpole pots” since I’d never before heard of the brand. I guess they’re good. They certainly function fine.
The pot codes indicate that these are Stackpole Electronics pots manufactured in the 41st and 49th weeks of 1974. This set of three Stackpole Pots from 1961/2 sold for $590 which is more than I paid for the entire guitar! That, of course, means nothing but it was one of the first pages I found when searching for “stackpole pots” since I’d never before heard of the brand. I guess they’re good. They certainly function fine.
There is no shielding in the cavity of this guitar which is another difference from the high-end S300 which had its control cavity completely shielded in copper. My guess is that this to reduce costs for an entry-level instrument, though maybe the beginner would complain about buzzing and want to step up to a nice 300! I’ve seen marketing do stranger things, but in this case I’ll follow Occam’s lead and believe the simpler answer.
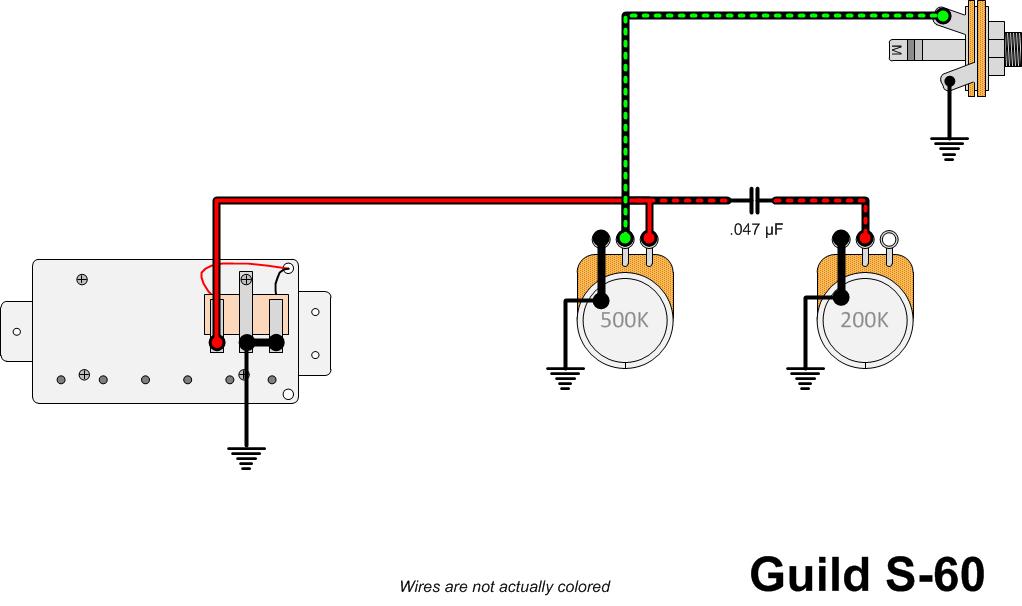 The schematic is pretty simple for this guitar, and I had to laugh at myself as I repeatedly reached for the pickup selector switch that simply wasn’t there. This guitar does one thing and it does it well: it delivers killer bridge pickup tones. If you don’t like the tone as it is, go buy a pedal. I hear a Big Muff Pi into a 200 watt Peavy head driving two Traynor PA towers sounds pretty good, especially for jazz.
The schematic is pretty simple for this guitar, and I had to laugh at myself as I repeatedly reached for the pickup selector switch that simply wasn’t there. This guitar does one thing and it does it well: it delivers killer bridge pickup tones. If you don’t like the tone as it is, go buy a pedal. I hear a Big Muff Pi into a 200 watt Peavy head driving two Traynor PA towers sounds pretty good, especially for jazz.
Hardware
 The bridge and tailpiece on this guitar, so far as I can tell, is identical to the ones on my high-end S300. The big block of brass that is the tailpiece is likely one of the reasons why this guitar is so acoustically resonant.
The bridge and tailpiece on this guitar, so far as I can tell, is identical to the ones on my high-end S300. The big block of brass that is the tailpiece is likely one of the reasons why this guitar is so acoustically resonant.
The strap pegs are typical of this era Guilds and the end strap peg is like the one on my S300 and M75 in that it is press-fitted into the guitar. This one appears to be quite snug, but in the low humidity winters of NJ it wouldn’t surprise me to have it pop out like all the others I’ve owned.
 If this guitar has a weakness it’s the tuners. They’re open gear affairs and the tuner pegs feel cheap. Three of the pegs seem to have what feels like a bit of flash where the two halves were pressed together and the excess wasn’t trimmed, though I’m not sure that’s really what happened. I don’t know what the ratio is on these tuners, but they’re nowhere near the power of the Gotohs on my S300. Compared to that guitar, these tuners just feel cheap, which I imagine to be because they are. They do a reasonably good job of keeping the guitar in tune but they do seem to not hold quite as well as the Gotohs and Grovers that I’m used to, though they are nothing like some of the super-cheap tuners I’ve seen on other entry level guitars from the ’70s.
If this guitar has a weakness it’s the tuners. They’re open gear affairs and the tuner pegs feel cheap. Three of the pegs seem to have what feels like a bit of flash where the two halves were pressed together and the excess wasn’t trimmed, though I’m not sure that’s really what happened. I don’t know what the ratio is on these tuners, but they’re nowhere near the power of the Gotohs on my S300. Compared to that guitar, these tuners just feel cheap, which I imagine to be because they are. They do a reasonably good job of keeping the guitar in tune but they do seem to not hold quite as well as the Gotohs and Grovers that I’m used to, though they are nothing like some of the super-cheap tuners I’ve seen on other entry level guitars from the ’70s.
That actually brings up a point I’ve made before, which is the fact that during the ’70s damn-near everything in the US was declining in quality, but even this, the lowest end of the Guild electric line circa 1977, exudes quality in almost every way. Yes, the tuners are a weak spot, but the guitar is still great. In fact, the rest of the guitar is so well made that it makes the tuners seem worse than they probably are.
 A note is in order about the knobs. The eBay seller made a point of stating that the knobs were not original, likely because they don’t look like the G-shield knobs on an S300 or even other S-60s. They may have also been told by someone that they weren’t, but having owned one of these guitars back in the late ’70s, I recognized them right away as the original proper knobs.
A note is in order about the knobs. The eBay seller made a point of stating that the knobs were not original, likely because they don’t look like the G-shield knobs on an S300 or even other S-60s. They may have also been told by someone that they weren’t, but having owned one of these guitars back in the late ’70s, I recognized them right away as the original proper knobs.
Later examples did include the iconic G-shield knobs, but the early S-60s had these sort of Fenderish knobs while the early S-300s actually came with odd-looking knobs as well. I think it was around 1979 that they both changed to the G-shield knobs, but don’t quote me on that as I have absolutely zero proof other than the fact that I owned a ’79 S300A-D that had the newer knobs.
Sound
 This guitar is not about flexibility. With its one pickup, one volume, and one tone, there’s not a whole lot of variation to be had, and as I joked above, that’s what pedals are for. Or, you know, amps.
This guitar is not about flexibility. With its one pickup, one volume, and one tone, there’s not a whole lot of variation to be had, and as I joked above, that’s what pedals are for. Or, you know, amps.
As I recorded the sound samples I noticed a lack of oomph while trying to push a high-gain amp which may be why the previous owner swapped out the pickup for something more substantial (The Classic ’57 I removed measured at 8.5k Ω). I like my bridge HB-1s to be very close to the strings and this helped a great deal, but this guitar doesn’t quite have… something… that my S300 has. I felt like I had to work a little harder to get this guitar to sing whereas my S-300 makes that absolutely effortless.
A very observant member (Zelja) of the Let’s Talk Guild forum noticed that the bridge pickup seemed to be closer to the bridge on the S-300 than it is on the S-60, so I pulled them both out and measured. I found that the S-60’s pickup is indeed 1/3″ farther from the bridge than it is on the S-300 which could have a fair bit to do with the difference in tone and feel between the two guitars.
Tiny Tweed
Open Chords #1
Open Chords #2
D-Shape
7th Chords
JCM 800
A Barre Chords
Evil 800
Barre Chords
Backline
D-Shape
Since this guitar has no switches, I did something a little bit different. For this guitar I recorded each selection with the tone set to 10, then 7, then 0. I chose 7 as the middle because the majority of the tone change happens between 5-10 so 7 is the real middle of the sweep. This test reminded me why I rarely use the tone knobs on my guitars. I love the tone on ten, I’m more or less ambivalent about the tone on seven, and I flat out dislike the tone on zero.
I’ll be honest and say that while I like the tone, I’m not wowed by it though an overdriven amp, but I do like it a lot when played through a clean amp. The chimey nature of the HB-1 really shines through on the Tiny Tweed and the same is true when I play it through my clone home-built tweed Champ. When I try and push an amp, though, the guitar seems to fight me a bit and the effortless sustain I’m used to from my S300 seems to be lacking. That could be due to the lower mass in this guitar or maybe because the pickup has lower output. I’m not really sure, but I think this particular guitar may be more suited to clean or edge-of-breakup tones instead of the higher-gain stuff.
Remember, this is the lowest resistance I’ve ever measured on an HB-1, so that could have a lot to do with it. This is also the lightest of the similar type Guilds I’ve played, so that could also have an impact. Hell, the two factors together could be the reason for the lack of power.
Remember, too, that I’m being super critical as a guy who’s owned scores of Guilds and has meticulously analyzed all of them. This is not a boutique instrument. Like I wrote above: this is not a guitar for measuring. It’s a guitar for playing, and it does that well because it’s still a tremendously well-made instrument.
Playability
 This guitar plays every bit as well as my more expensive and high-end S-300. OK, maybe not every bit as well, but the biggest difference in feel for me is the rosewood vs. ebony boards. The rosewood on this guitar is damn nice, though, so that’s not a huge deal. I can feel the difference in the two guitars with my eyes closed, but again remember that I’m a nutty collector who spends too much time fondling, er, examining his Guilds.
This guitar plays every bit as well as my more expensive and high-end S-300. OK, maybe not every bit as well, but the biggest difference in feel for me is the rosewood vs. ebony boards. The rosewood on this guitar is damn nice, though, so that’s not a huge deal. I can feel the difference in the two guitars with my eyes closed, but again remember that I’m a nutty collector who spends too much time fondling, er, examining his Guilds.
This guitar is a pound lighter than my S300, so it’s more comfortable to play for long periods. The shape, while odd looking to some, is actually really well designed for standing or sitting and with it’s long neck and thin body is just a joy to play. With it’s very curved fretboard there is no fatigue while playing and with its excellent setup there is no fretting out.
With its single pickup there’s plenty of room for me to abuse the strings without hitting anything I shouldn’t, and with a lack of controls to get in the way, I can wail on this thing like nobody’s business, which I do. A lot.
Conclusion
I like this guitar, and though it’s not the equal of the high-end S300, it wasn’t meant to be. To be honest, there is a fair bit of nostalgia in these models for me, but the fact remains that they are still great guitars. They are also very simple guitars and that can have a charm of its own. There’s no high-end bling to distract you from the fact that you should probably practice more.

My only real complaint is the tuners. I really don’t like them and I remember not liking them as a teen who barely knew any better. I even like the simple headstock with its lack of veneer or sexy inlays because it matches the color of the body. The guitar is simple, honest, and delivers, though depending on your musical style you might want a pickup with more output. For me, the jangly character of the HB-1 is everything I need in a guitar and while I won’t be using this one for my George Lynch impressions (he was the guitarist for the hair-band Dokken for those not obsessed with the genre), it definitely has its place where less power and more character is the order of the day.

The only problem I see in buying one of these is that too many people want too much money for them. In 2017 I bought a mint Guild S-300 for $1000. If an S-300 is $1000, then an S-60 shouldn’t be $1200 – I don’t care how good it looks or what condition it’s in.
Backline
One More Time!
Donate: PayPal Crypto:
ETH: 0x0AC57f8e0A49dc06Ed4f7926d169342ec4FCd461
Doge: DFWpLqMr6QF67t4wRzvTtNd8UDwjGTQBGs
Ibreally appreciated your articles on the Guild S300 and Guild S60 as well…
I bought a Guild S60d at a pawn shop in my early 20’s for $300.00 in tiny payments and played it through a Randall Alpha II which had “Crimson & Clover” (vibrato feature). The amp waa also a whoppung $300.00 from, I believe, Prudential loan on 6th Street in SF…
Thirty Several years later I have that once pristine and now well worn and chipped S60Dimarzio (2 single coils) and Three (3) Black S300s – (2 are D’s) and a S300AD that somebody just has to paint blue… And I’m looking at an S60d same as my first guitar (but not thrashed) as I have the same nostalgic feelings about S60D’s with dual single coill Super DistortionvDimarzios that you have about yours with the sungle HB1…
The new acquisistions are running about three to four times what I paid for my Pawn Shop special. I bought it because it looked different maybe even sort of “Punk” it was early 80s and that was the thing. I learned toplay on a Guild – switched to Gibson Les Pauls – and now I have Guilds by choice – on purpose… Marshalls too. Again I truly loved your articles with all my heart and soul. We love the same Axes. Thats so absolutely cool. Have fun. Doug
Hey Gary, Great post about the Guild S60! I’ve got a white 1978 Guild S60 that I bought used in 1980 for $125. Hands down, it’s the best electric guitar I’ve ever played–great playablility and awesome sound, even with just the single humbucker–or perhaps I should say because it’s just got the single humbucker. I’ve owned Strats, Les Pauls, etc., but this “entry level” Guild is my favorite in every way.
There’s a photo of my S60 on my SoundCloud page, and the S60 is featured on pretty much all the songs (particularly featured on “About You.”) I just can’t get this sound from any other guitar!
https://soundcloud.com/penelopes-thrill
I’ve also got a 1980 S60D–two single coil pickups–and a 1966 Guild Starfire XII, which, in my opinion, is the best electric twelve string ever made. This is the secret known only by the select few: Guild electrics are the best!!
p.s., I’m also originally from New Jersey
I bought one around 1980, put a Seymour Duncan JB in it and it was a smokin’ hot guitar. I got it for $200.00. The original pickup had feedback issues, which is why I replaced it.
I joined a classic rock cover band back in ’95 after a 15 year hiatus from performing. I had sold my ’76 SG and Marshall 100 watt combo years before and kept my 12 string acoustic for personal entertainment. After my first gig with the band, the guys gave me an old ’78 S60 in lieu of my cut of the gig pay (which was around $45 or so). I’ll call that the best deal of my life, because after a little work, it has turned out to be my favorite. I now also have a Strat and a Les Paul. I’ve bought and sold quite a few guitars since then, and do all my own maintenance, and I don’t think I’ll ever get rid of this S60. It plays so well. Someone did add a Kahler tremolo so the body is routed out for it, which pretty much ruins any chance of restoring to original condition. I’m pretty sure it wasn’t available that way. They did a decent job though. It’s white’ which has aged to almost a TV Yellow. The original tuners don’t agree very well with tremolo, but since I only use tremolo gently, haven’t yet opted for better tuners. Really a nice guitar. You mentioned yours had a maple neck? Mine is most definitely a mahogany neck and according to the s/n is a ’78 model year.
Saw James McMurtry playing one last night through a 63 Vibroverb in Bloomington Ind.
Oh Gary, our Guild affair continues…..
Bought a white one new in 1978 I believe. It’s on its third pickguard, fourth pickup, and I stripped the paint off in the 80’s so it’s natural mahogany. I still have the original pickup, it’s in a 1980 Fender Bronco that I got for my 18th birthday – all my friends chipped in and got it for me.
My X60 still plays like a dream. I don’t know if I’ve ever touched the truss rod. So many gigs, so many lessons, so many songs learned on it. My oldest remaining companion!
Cheers,
Fatboy
Great writeup on a classic Guild, enjoyed reading that! I have a ’77 S-60 in cherry finish identical to the one you have. I bought mine off of a failed guitarist buddy in college back in the late 80s. It was basically mint, case-kept since he got it as a kid. He charged me $20 for it. I felt guilty, so he also let me buy him a calzone and split a pitcher of beer for his trouble. Best money I’ve ever spent. Still love that guitar and I play it to this day. In fact, I just uploaded a video to my youtube channel where I used it in a Misfits cover song I did with my son. Take a look if you care to check it out:
https://www.youtube.com/watch?v=rEoG14cWqbQ
Cheers!
Grizmit
Very cool and thanks for sharing! $20, calzone and half a pitcher of beer is a damn good price!
Haha, I know right? I still joke my buddy about that especially considering the current $1200 price tag at Norm’s.
Actually, here is the live recording where the Guild is iso’d before we layered in additional tracks.
https://www.youtube.com/watch?v=ms4h8SSzi0A
My first electric guitar was a Guild S-60D, the model with two single coil pickups. Purchased from Sam Goody’s in Philadelphia in ’78. Like a dolt, I sold it to a friend back in ’93 or so. He really wanted it, I wasn’t playing guitar, my first-ex-wife encouraged the sale, etc. Long story short, it’s on its way back! Basically for the cost of shipping plus new case to ship it in.
It’s not pristine — my pal installed a Bigsby and pulled all the electronics (he ran it with a single Hot Rail in the bridge position). I know that the original tailpiece is coming back, and I know where one of the original pickups is, but I’ll likely have to replace the knobs, switch, & pots. Still, it’s a swell Christmas present.
Love it – congrats.
I managed to acquire a short scale Guild S-60 3/4
I’ve never seen one before, never even knew they existed until a family friend asked if i wanted “an old beat up guitar” that had been sitting in her living room for nearly 30 years.
It needed a whole lotta love to restore (which I’m putting into a YouTube vid someday when I’m not lazy) but everything you said in this article about its big brother rings true for the 3/4 sized one. Yes those tuners are garbage!
Have you ever encountered the 3/4 model?
Not only have I encountered one – I have one! And not only do I have one, but it’s one of the next reviews I’ll be publishing! Stay tuned. 🙂
I bought an S-300D a few years ago in part to match my B-301 bass. I know this isn’t a bass blog but I had a B-301 in high school (purchased in ’78), foolishly sold it in college and finally got another 37 years later (don’t do the math). Truly one of the best basses out there. I became obsessed with all things late 70’s Guild solid body. I loved the S300D but honestly the DiMarzios were just too hot for my tastes. I really wanted the real Guild humbuckers. I sold the S300D…hated myself … had the opportunity to buy it back…didn’t…hated myself anew…. but just got a ’77 S-60 (arrived today). Hell yeah! This is the sound I remembered and wanted. As noted, the tuners kinda suck but basically work and the rosewood fretboard, while nice, isn’t as nice as the ebony on the S-300D but otherwise it is every bit as well put together. I love the simplicity of a single pickup. I’m selling my ’95 S-100 on Reverb as well. Another super nice guitar but the cream of real deal Guild humbuckers can’t be beat. I’d love an S-300 (non D) but these are few and far between. Plus, since I have a B-301, the matching single pickup and pickguard shape of the S-60 is making me smile unreasonably. Thanks GAD for all the helpful knowledge over the past few years. I hope you and the Newfies are well.
Thanks for the great comment! I have a small collection of Guild basses including a B-301, so don’t be surprised if you see a review of one someday (hopefully but probably not) soon!
This made me laugh. This guy on craigslist pretty much sums it up for the S-60D. The best guitar ad copy so far this year. Enjoy.
https://sfbay.craigslist.org/sby/msg/d/santa-clara-guild-60d/7589434426.html
[GAD] – Saved here: https://www.gad.net/Blog/wp-content/uploads/2023/02/Guild-S60D-Modified-Craigslist-Ad-2023.png
I can’t stop laughing! That dude should be head copy writer for a multi million dollar advertising firm. He certainly missed his calling…….
Bought a slightly used Guild S-60D in 1982 and to my surprise there was a brand new set of deluxe Schaller tuners in the nice case that came with the guitar. Like you I thought the original tuners were cheap, so I dove into replacing the originals with the Schallers. After removing the 3 in a row tuners, I was stunned to see that the neck holes were already pre- drilled from the factory to accept the Schallers. The original 3 in a row tuners had bushings on the pegs to fill the holes. All I had to do was install them tighten the top nuts down and drill tiny holes on the back of the headstock to secure them…..easy peasy. What a difference – the guitar can be spanked hard and stay in perfect tune. So, any of you that own these guitars and want to upgrade the tuners – you can do it in literally an hour or two.
But yes, these are very high quality(and severely underrated) guitars that may not be the most attractive electrics, but make up for it in their build quality, playability and sound quality. Still have the guitar 41 years later and play and record with it all the time – it never disappoints.
I had one like that exactly , the S-60 , can’t remember the year mine was, but listen to this Frankenstein story of mine,. My then wife’s cuzin, needed weed, so he sold the guitar to me for 50$ (canadian $) , it was the original brownish-red think paint with white dots all over, like if the guitar was on the floor while he painted his seeling. So the first thing i had done is remove the paint , it went well and i had discovered the beautiful wood grain , it was real neet like the one pictured here withoput varnish, i left mine straight to the wood no finish at all, ( love it like that ) .. the Thing is , i couldn’t afford another guitar and i was gigging all the time and didn’t make enough money, ( was already a dad and didn’t make enough $$) so i needed a neck pickup like a strat . Guess what i have done…. i took a rotor and carved a neck pickup hole near the 24 th fret , the rotor went weird and start to did everywhere , broke the pickguard ,(kinda exploded like ceramic ) took out some frets in the way , and finally didn’t finish the job, so i kinda killed the guitar , that i didn’t have a clue that would be so regretted today. when i needed cash to buy amp parts , i brought the guitar to a music store in Ste-Julie Québec , the guy at the store gave me a boat load of shit.. (what the F.#$%? have you done ) .. and on and on.
he said i could have gave you a brand new amp for that .. but you broke it so bad, i’ll give you 65$ for it ,the way it is!. so in need for parts now, i sold the battered axe to the man, and more than 30 year later , i still bang my dumb ass head on the wall for it. Never got over it , and when i saw the picture above, i thought , ok, lets make money and try to buy one for my retirement days. ( still don’t make money by the way , hired guns don’t get big dough in Quebec ) .. so there is my story . now if you’ll excuse me, i got to get back at banging my head on that old wall now, cheers all
This could be my guitar. I am seriously wondering if it was. I got it as a high school graduation present in 1985 and owned it until the mid-90s when I traded it in for a Gibson acoustic. I remember having issues with the intonation (that were probably more the result of my lousy playing) and fooling around with the bridge screws so much that I’m sure I made that worse.